Your phone buzzes at 3 AM. The AI-powered recommendation engine is producing bizarre product suggestions—winter coats for customers in Arizona, baby products for retirees. Customer support is flooded with complaints. Revenue is dropping in real-time.
What's your call? Shut down immediately and lose overnight revenue? Investigate while the system runs and risk further damage? Roll back to yesterday's version without knowing what broke?
This lesson equips you with a battle-tested framework to handle AI incidents with confidence—minimize damage, protect your organization's reputation, and restore operations efficiently.
Containment tactics that balance risk with business continuity
Communication protocols and escalation paths
Post-incident analysis and continuous improvement
🎯 Why this matters (WIIFM)
AI incidents surged 30% in 2024 (OECD data). As an operations manager, you're the first responder. This playbook reduces response time by 40%, limits business impact, and protects your reputation when seconds count.
Understanding AI Incidents
What Qualifies as an AI Incident?
An AI incident is any event where an AI system behaves unexpectedly, produces harmful outputs, or fails to meet operational requirements, potentially causing harm to users, the business, or stakeholders.
Key Characteristics:
Deviations from expected behavior or accuracy thresholds
Bias or fairness violations in outputs
Security breaches (adversarial attacks, data poisoning)
Performance degradation affecting user experience
Common Incident Types
Click each type to learn more ▾
Performance degrades over time as real-world data changes
Corrupt, incomplete, or biased input data
Malicious inputs designed to fool the AI
Infrastructure or integration breakdowns
Knowledge Check 1
Which scenario best describes an AI incident requiring immediate response?
A fraud detection AI suddenly flags 40% of legitimate transactions as fraudulent, disrupting customer service
An AI model's accuracy improves by 2% after routine retraining
The data science team schedules a planned maintenance window for model updates
A new AI feature is released and users provide positive feedback
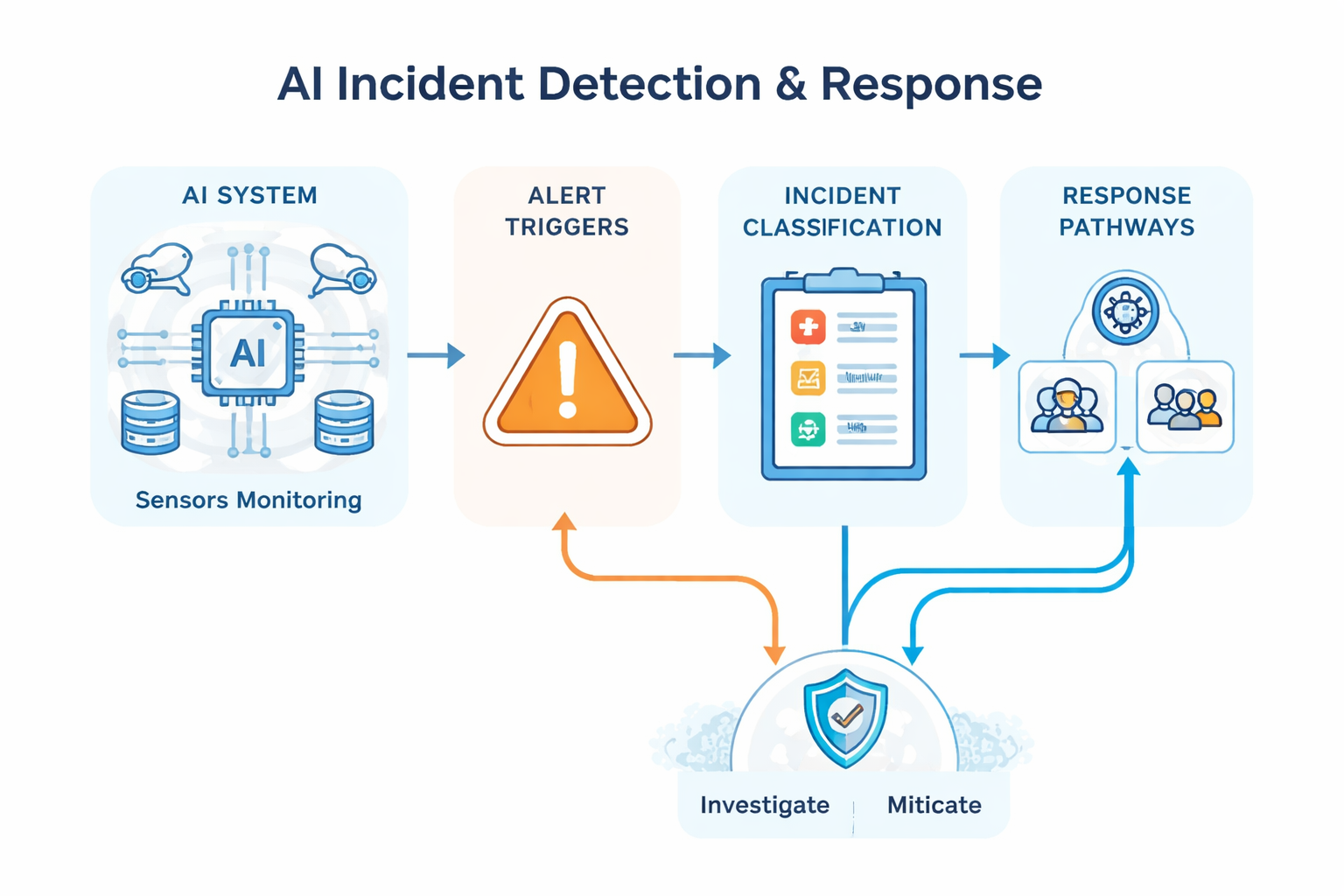
The Four-Phase Incident Response Framework
Adapted from NIST AI Risk Management Framework, this playbook organizes incident response into four actionable phases:
1. Detection & Identification
Recognize anomalies through monitoring, alerts, and user reports. Classify severity and scope quickly.
2. Containment
Limit the incident's impact. Isolate affected systems, pause deployments, or roll back to stable versions.
3. Mitigation & Recovery
Diagnose root cause, apply fixes, and restore services. Communicate with stakeholders throughout.
4. Post-Incident Review
Document lessons learned, update playbooks, and implement preventive measures to reduce future risk.
Phase 1: Detection & Identification
Early Warning Systems
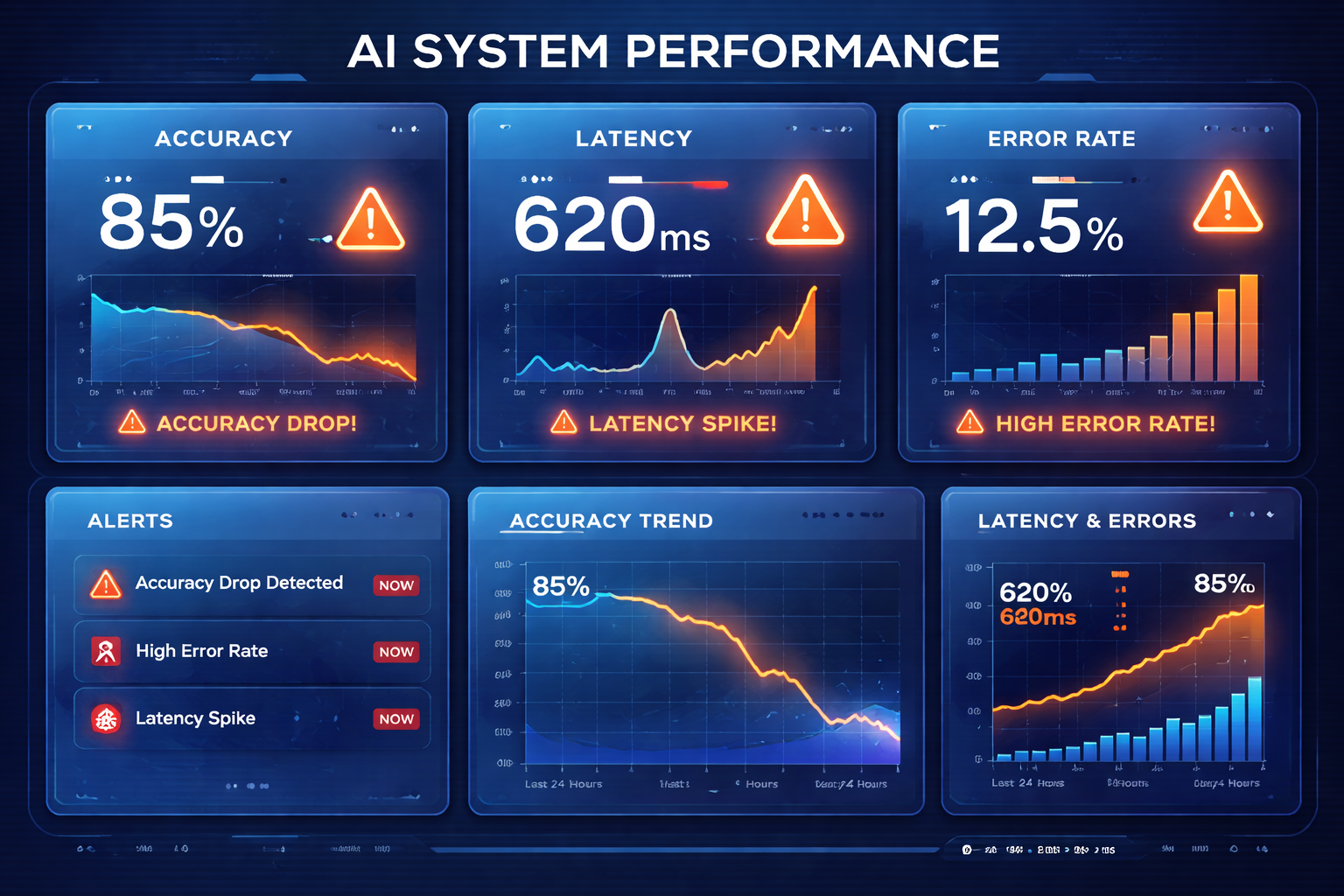
Effective detection relies on continuous monitoring across multiple dimensions. Implement automated alerts for:
Performance Metrics: Accuracy, precision, recall, F1 score drops
Data Drift: Input distribution changes vs. training data
Latency Spikes: Response time degradation
Error Rates: Increased exceptions or null predictions
Classification Matrix
Click a level to expand details ▾
Critical
Immediate harm to users or major business disruption (response within 15 min)
High
Significant impact, limited scope (response within 1 hour)
Medium
Moderate impact, manageable workarounds (response within 4 hours)
Low
Minor issues, minimal business impact (response within 24 hours)
Knowledge Check 2
Your AI chatbot's response latency jumps from 200ms to 3 seconds, and user complaints increase by 15%. What is the correct first action?
Classify the incident as High severity and initiate containment protocols immediately
Wait 24 hours to see if the issue resolves itself before taking action
Immediately shut down all AI systems without investigation
Classify it as Low severity and schedule a review for next week
Phase 2: Containment
Immediate Actions
The goal of containment is to stop the bleeding. Your response depends on incident severity and business impact:
Containment Tactics
Expand each tactic ▾
Switch to rule-based fallback or previous model version
Reduce load on affected systems while investigating
Disable specific AI features without full system shutdown
Revert to last known stable configuration
Reserved for critical incidents with immediate harm potential
Decision Framework: Balance business continuity against risk exposure. A minor accuracy drop may tolerate gradual remediation, while bias violations or security breaches demand immediate containment.
Phase 3: Mitigation & Recovery
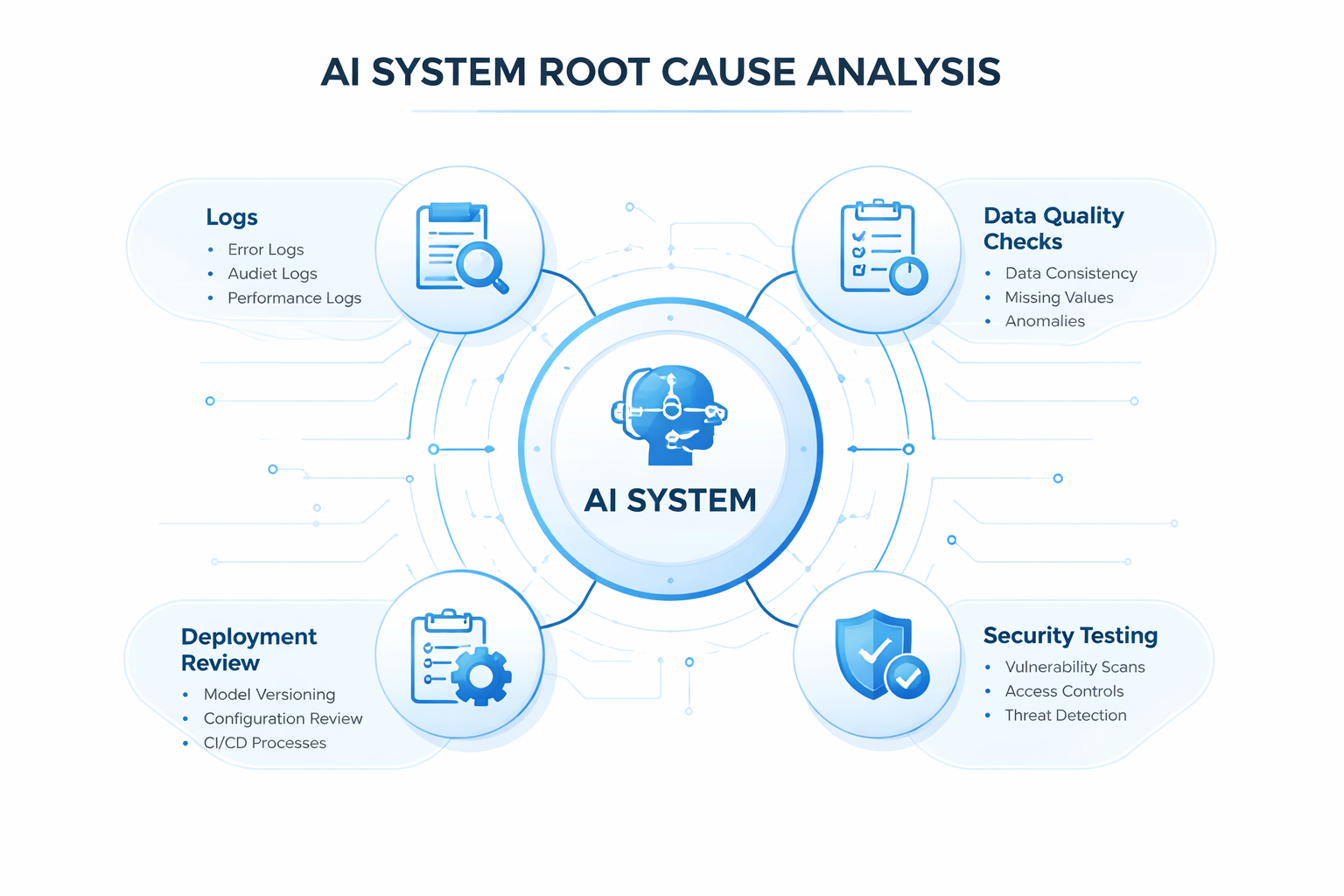
Root Cause Analysis
Once contained, conduct a systematic investigation to identify why the incident occurred:
Review logs, metrics, and system changes preceding the incident
Analyze input data for quality issues or distribution shifts
Test for adversarial patterns or security vulnerabilities
Interview team members and review recent deployments
Recovery Strategies
Data Issues: Clean corrupted data, adjust preprocessing pipelines
Model Drift: Retrain with recent data, adjust thresholds
Validate fixes in staging before production deployment. Gradually restore service with enhanced monitoring.
Knowledge Check 3
After containing an AI incident, you identify model drift due to seasonal data changes. What is the most effective recovery action?
Retrain the model with recent data including seasonal patterns, validate in staging, then deploy with enhanced monitoring
Immediately deploy the original model without any changes or testing
Permanently disable the AI system and rely solely on manual processes
Ignore the seasonal pattern and continue using the current model without adjustments
Phase 4: Post-Incident Review
Conduct a Blameless Retrospective
Within 48 hours of resolution, gather the incident response team for a structured review. Focus on learning, not blame.
Key Review Questions
What happened and when was it first detected?
What was the root cause and contributing factors?
How effective was our detection and response?
What worked well and what needs improvement?
What preventive measures can we implement?
Action Items
Document and implement improvements:
Update monitoring thresholds and alert rules
Refine incident classification criteria
Enhance testing and validation procedures
Update playbooks with lessons learned
Communication & Escalation Protocols
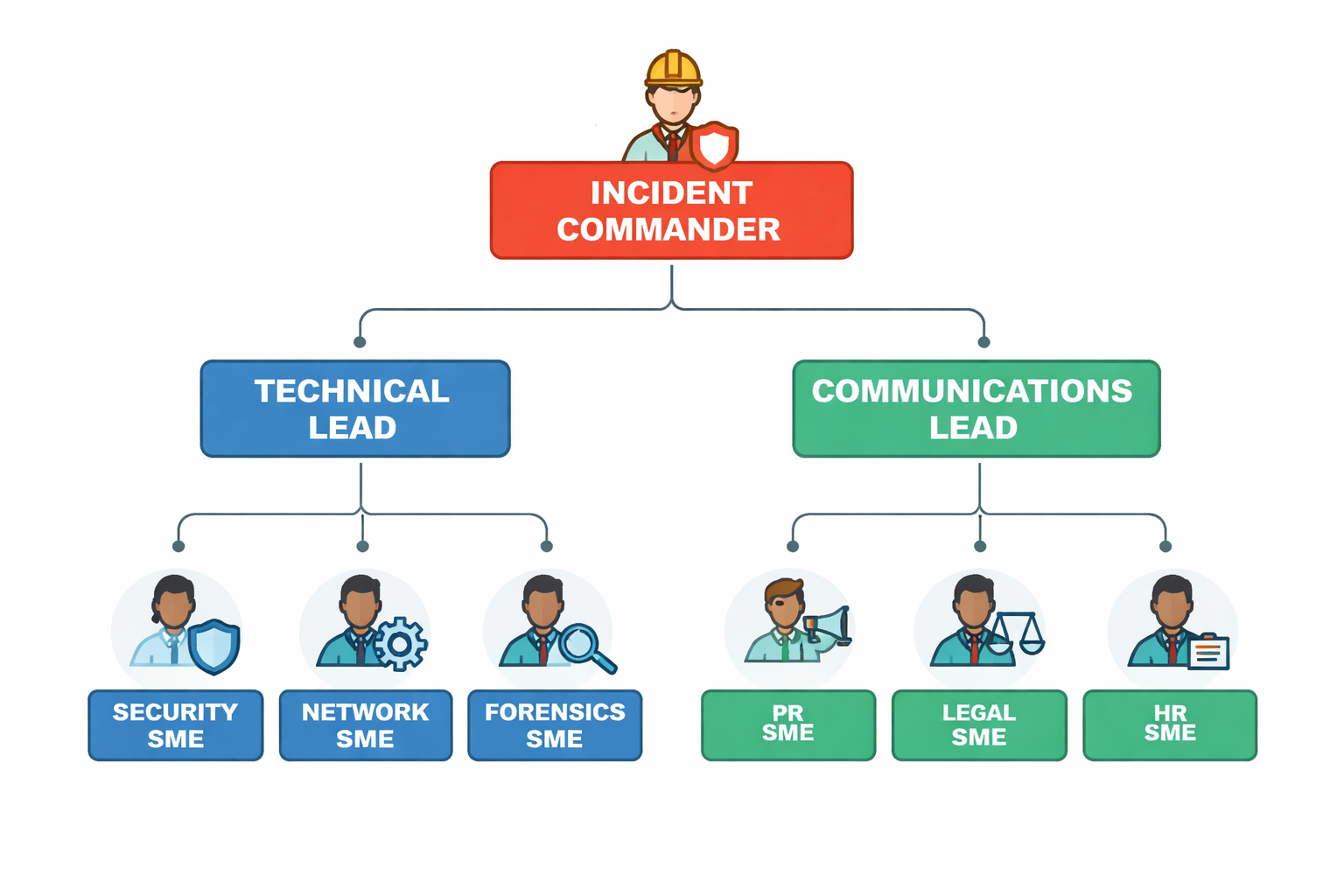
Build Your Response Team
Assign clear roles and responsibilities before incidents occur:
🎖️ Incident Commander
Coordinates response, makes containment decisions
🔧 Technical Lead
Diagnoses issues, implements fixes
📢 Communications Lead
Manages stakeholder updates
🧠 Subject Matter Experts
Data scientists, ML engineers, security specialists
Escalation Paths
When to escalate:
Critical severity incidents automatically escalate to senior leadership
Incidents exceeding response time SLAs
Cross-functional impact (legal, compliance, PR)
Potential regulatory or safety implications
Building Resilient AI Systems
Proactive Risk Management
The best incident response is prevention. Integrate these practices into your AI operations:
📊 Comprehensive Monitoring
Track performance, data quality, fairness metrics, and security indicators continuously with automated alerting.
🧪 Robust Testing
Implement pre-deployment validation, stress testing, adversarial testing, and canary releases to catch issues early.
🏛️ Governance Framework
Establish AI governance committees, maintain system inventories, and enforce approval workflows for changes.
🔍 Regular Audits
Conduct periodic reviews of model performance, bias assessments, security scans, and compliance checks.
Culture of Accountability
Foster a culture where team members feel empowered to raise concerns, report anomalies, and challenge assumptions. Psychological safety accelerates detection and improves response quality.
Key Takeaways
Your AI Incident Response Playbook
You've learned a structured, proven framework to manage AI incidents with confidence. Here are the essential points to remember:
1. Recognize & Classify
Monitor continuously. Detect anomalies early. Classify severity quickly to match response urgency.
2. Contain the Impact
Stop the bleeding with graceful degradation, rollbacks, or feature flags. Balance business continuity with risk.
3. Diagnose & Recover
Conduct root cause analysis. Apply targeted fixes. Validate before production. Communicate transparently.